Decision Transformers
Decision Transformer
- Paper: Decision Transformer: Reinforcement Learning via Sequence Modeling - NeurIPS 2021
- [Website] [Code]
 Illustration from the corresponding paper.
Illustration from the corresponding paper.
 Illustration from the corresponding paper. Decision Transformer Pseudocode for continuous actions.
Illustration from the corresponding paper. Decision Transformer Pseudocode for continuous actions.
The following statements from the paper are key to understand this model:
- “Unlike prior approaches to RL that fit value functions or compute policy gradients, Decision Transformer simply outputs the optimal actions by leveraging a causally masked Transformer. By conditioning an autoregressive model on the desired return (reward), past states, and actions, our Decision Transformer model can generate future actions that achieve the desired return. Despite its simplicity, Decision Transformer matches or exceeds the performance of state-of-the-art model-free offline RL baselines on Atari, OpenAI Gym, and Key-to-Door tasks.”
- “States, actions, and returns are fed into modality- specific linear embeddings and a positional episodic timestep encoding is added. Tokens are fed into a GPT architecture which predicts actions autoregressively using a causal self-attention mask.”
- “We will train transformer models on collected experience using a sequence modeling objective.”
In my understanding, training a decision transformer is a supervised learning. By using offline data, the model is trained to anticipate an action that shares the same pattern in the offline data, given the current history.
Trajectory Transformer
- Paper: Offline Reinforcement Learning as One Big Sequence Modeling Problem - NeurIPS 2021
- [Website] [Code] [Blog]
A Generalist Agent: Gato
 Illustration from the corresponding paper
Illustration from the corresponding paper
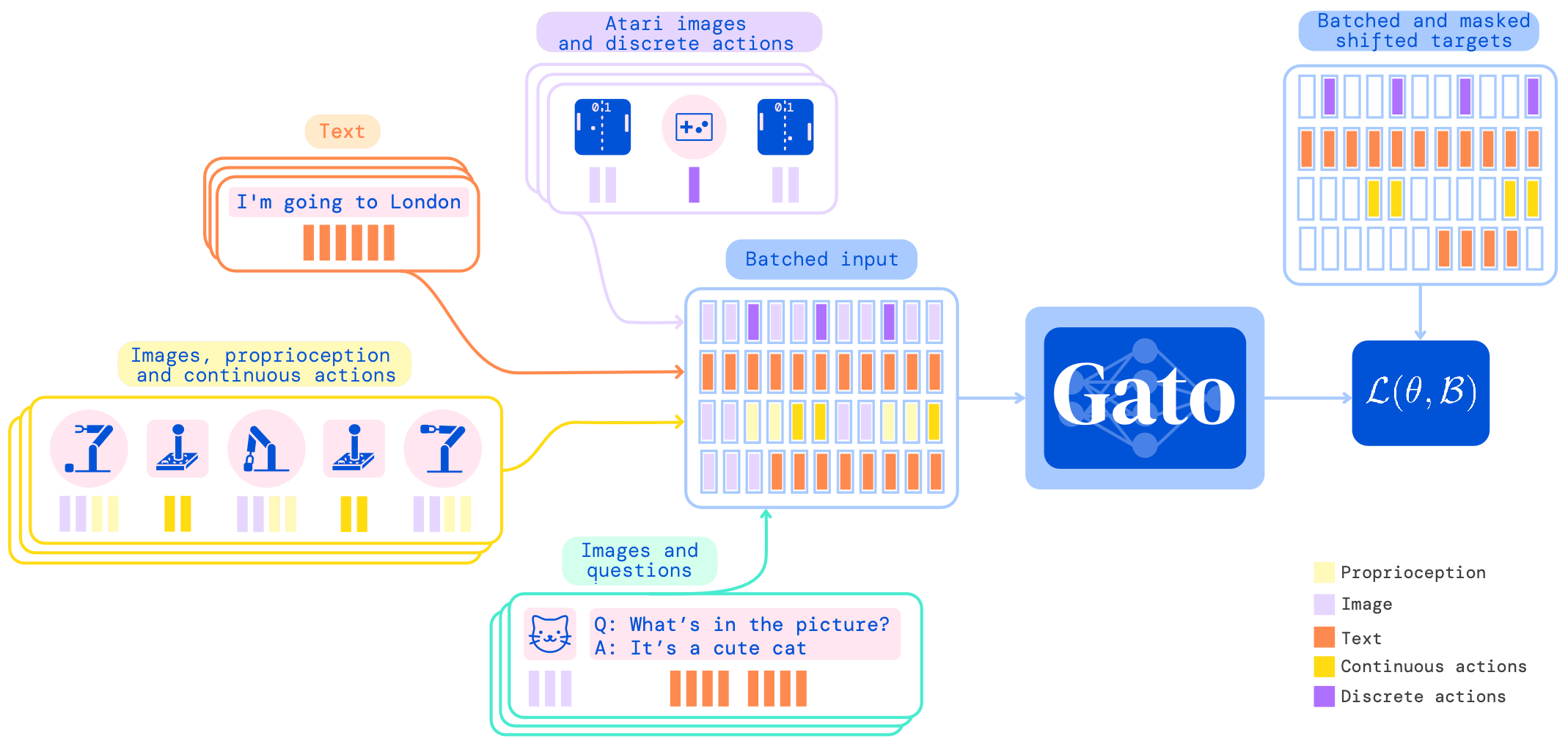 Illustration from the corresponding paper. Training phase of Gato.
Illustration from the corresponding paper. Training phase of Gato.
 Illustration from the corresponding paper. Running Gato as a control policy.
Illustration from the corresponding paper. Running Gato as a control policy.
The following statements from the paper are key to understand this work:
- “The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens.”
- “Gato was trained on 604 distinct tasks with varying modalities, observations and action specifications.”
- “Gato consumes a sequence of interleaved tokenized observations, separator tokens, and previously sampled actions to produce the next action in standard autoregressive manner. The new action is applied to the environment a game console in this illustration, a new set of observations is obtained, and the process repeats.”
In my understanding, Gato is a decision transformer trained on various tasks using offline data. In different tasks, the tokenization is different but the core of the network shares the same one.
Multi-Game Decision Transformer
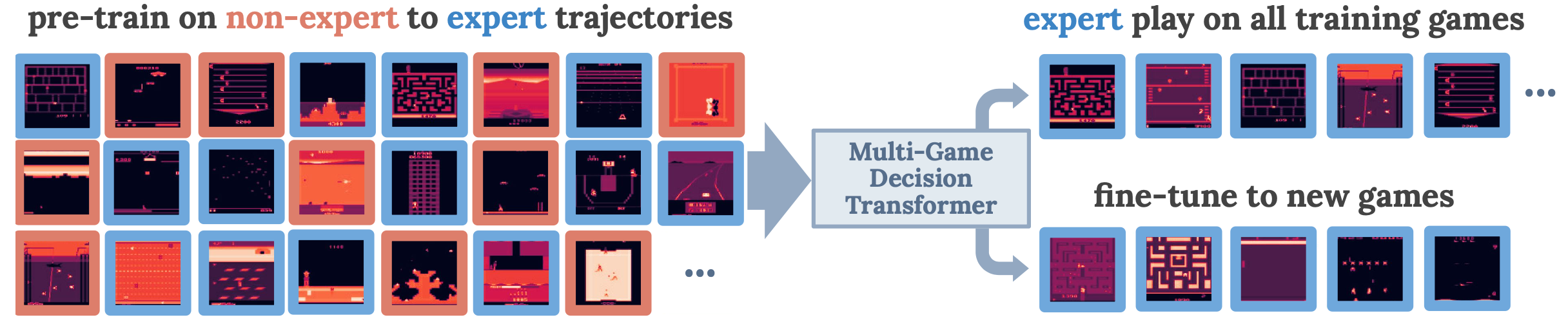 Illustration from the corresponding paper. An overview of the training and evaluation setup.
Illustration from the corresponding paper. An overview of the training and evaluation setup.
The following statements from the paper are key to understand this work:
- “We observe expert-level game-play in the interactive setting after offline learning from trajectories ranging from beginner to expert.”