Technology
Multi-Agent Reinforcement Learning | 多智能体强化学习中的信息设计
Yue Lin, Wenhao Li, Hongyuan Zha, Baoxiang Wang. NeurIPS 2023. This is currently my most representative work.
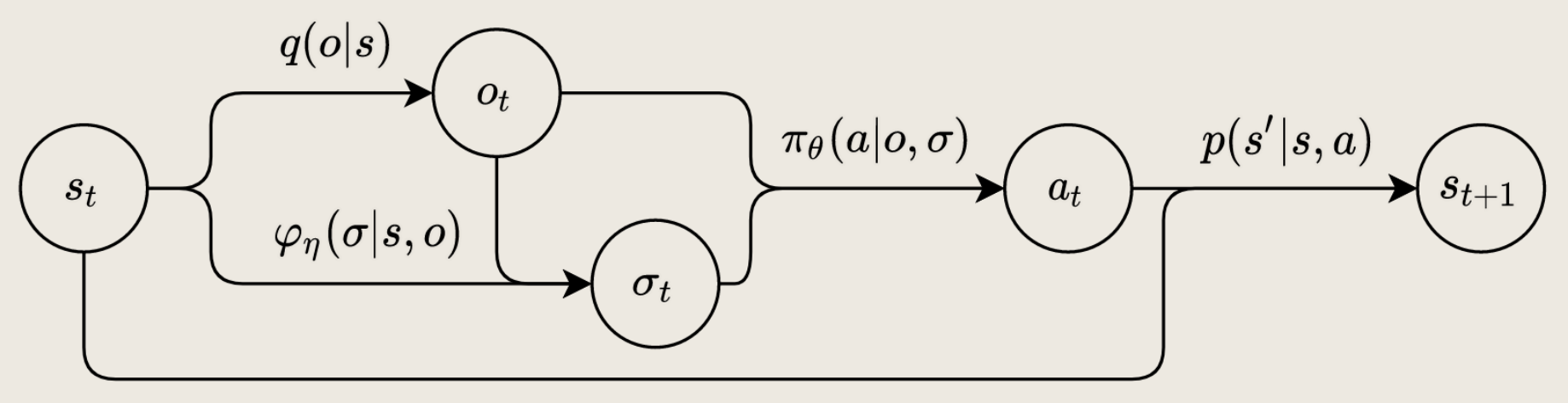
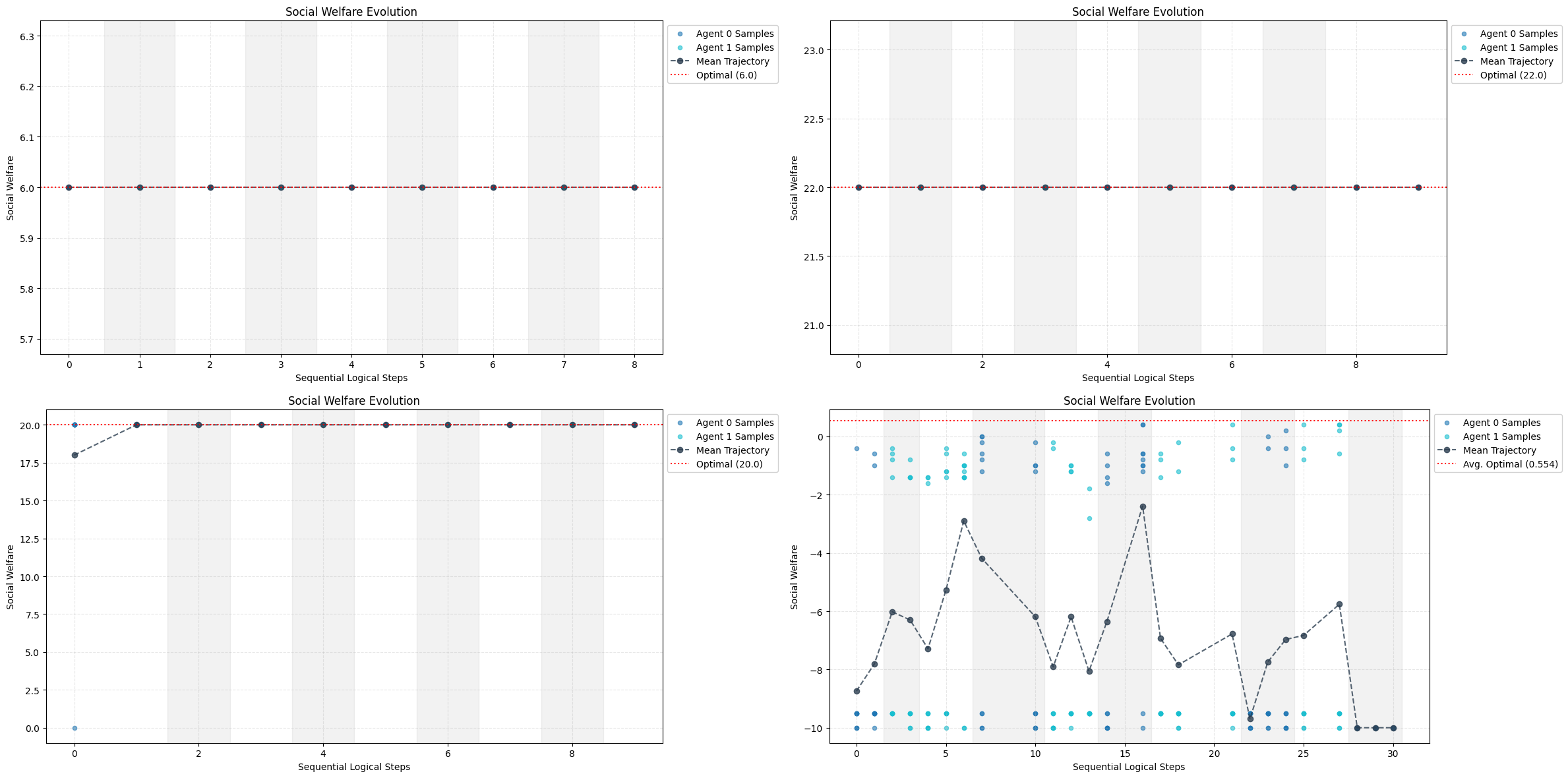
Multi-Agent Reinforcement Learning | Information Design in Multi-Agent Reinforcement Learning
Yue Lin, Wenhao Li, Hongyuan Zha, Baoxiang Wang. NeurIPS 2023. This is currently my most representative work.
Economics & Game Theory | Information Design in 10 Minutes
A brief introduction from the perspective of BCE (Bayes correlated equilibrium), with some examples.
Economics & Game Theory | Information Design
A sender with informational advantage wants to send messages to steer a receiver's action policy. They may have different objects. Information design is to optimize the sender's signaling schemes.
Machine Learning Basics | Anthropic's J-Space: A Global Workspace Inside Language Models
从残差流、Jacobian Lens 与稀疏表示出发,解释 Anthropic 的 J-space 如何暴露语言模型未说出口的中间概念,实验如何证明它参与报告、控制和推理,以及为什么这些结果并不能证明 Claude 具有主观意识。
Unfinished | The Bitter Lesson and Reward is Enough: Sutton's Two Principles of Intelligence
从 Sutton 2019 年的 The Bitter Lesson 与 Silver、Singh、Precup、Sutton 2021 年的 Reward is Enough 出发,区分“可扩展的通用方法”为何常胜于人工知识,以及“奖励为何可能驱动智能能力涌现”;并讨论二者的联系、边界、对 LLM 与强化学习研究的启示。
Unfinished | From Noise to Data: An Introduction to Diffusion Models
⚠️ 本文尚在撰写中,内容未完成,后续会继续补充与修订。 本文由 Claude Code 生成。系统梳理扩散模型的核心脉络:前向加噪与反向去噪、DDPM 的变分推导与简化目标、分数匹配与 SDE 统一框架、DDIM 与引导采样、潜空间扩散等,关键名词附原文。仅为学习笔记,非权威综述。 扩散模型(diffusion models)是当前生成式建模的主导范式。从 Stable ...
Unfinished | Policy-Conditioned Policies for Multi-Agent Task Solving
Yue Lin, Shuhui Zhu, Wenhao Li, Ang Li, Dan Qiao, Pascal Poupart, Hongyuan Zha, Baoxiang Wang. arXiv preprint 2025.
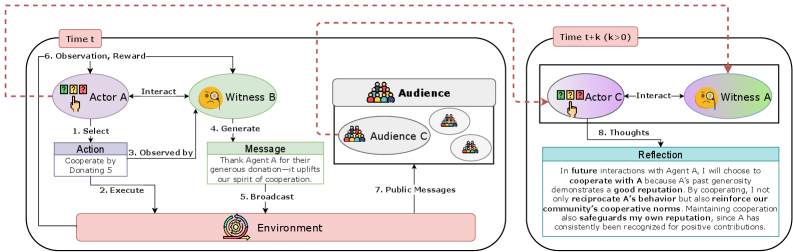
Unfinished | Talk, Judge, Cooperate: Gossip-Driven Indirect Reciprocity in Self-Interested LLM Agents
Shuhui Zhu, Yue Lin, Shriya Kaistha, Wenhao Li, Baoxiang Wang, Hongyuan Zha, Gillian K Hadfield, Pascal Poupart. ICML 2026.
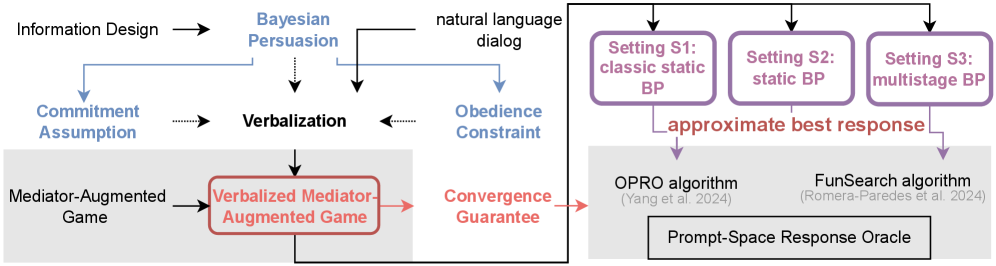
Unfinished | Verbalized Bayesian Persuasion
Wenhao Li, Yue Lin, Xiangfeng Wang, Bo Jin, Hongyuan Zha, Baoxiang Wang. ICML 2026.
Algorithm | Dynamic Programming
动态规划(Dynamic Programming, DP)是算法里最重要、也最让初学者头疼的思想之一。本文从最朴素的重复计算讲起,一步步建立 DP 的核心直觉与设计套路,再精讲一批经典 LeetCode 题,最后揭示它与强化学习之间的血缘:Bellman 方程其实就是 DP,而强化学习是它在模型未知、状态爆炸时的近似版本。 动态规划是什么:从重复计算到记忆化 动态规划(Dynamic P...
Algorithm | A* Search Algorithm
A*(A-star)是图与网格上最常用的最短路径搜索算法,它把 Dijkstra 的“稳”和贪心最佳优先搜索的“快”合二为一。本文从最短路径问题与这两个前辈算法讲起,一步步把 $f(n)=g(n)+h(n)$、最优性条件、启发式设计与常见变体讲清楚,只需要基础的图与优先队列知识即可跟下来。 问题与起点:最短路径、Dijkstra 与贪心最佳优先 在动手讲 A* 之前,我们得先把舞台搭好。...
Algorithm | Computational Complexity: P, NP, PPAD and Game Theory
本文由 Claude Code 生成(联网检索文献后整理)。讲清算法复杂度的常用类(P、NP、co-NP、PSPACE、#P、以及 TFNP 一家的 PPAD、PLS、CLS 等)、常见归约,以及常见结论,尤其是博弈论与信息设计(含 Bayesian persuasion)相关的难度结果。仅供学习。 算法复杂度回答的不是”这个问题怎么解”,而是”这个问题到底有多难、难在哪里”。本文从最基...
Economics & Game Theory | Auctions and Mechanism Design
本文是拍卖理论(auction theory)与机制设计(mechanism design)的期末速通笔记:深入浅出,但覆盖所有核心考点,每个定理都给准确陈述、关键定理给出证明、并配小例子。读完并复习后,应足以在期末考中拿到高分。 拍卖入门:模型与四种标准拍卖 本节是整个拍卖理论的地基。我们先回答一个根本问题:拍卖到底要解决什么问题?再建立刻画买家估值的两类价值模型,重点打磨独立私人价值...
Reinforcement Learning | MS-Swift GRPO Pipeline Walkthrough
基于源码 walkthrough 拆解 ms-swift 的 GRPO 训练管线:项目目录地图、调用链、scheduler/turn/trajectory/rollout 概念、训练前向与数据流、逐文件骨架,以及如何修改 forward pass、loss 与梯度并完成注册。
Unfinished | Mean-Field Game
从 N-player 随机微分博弈出发,取 N 趋于无穷的平均场极限,得到 HJB-Fokker-Planck 耦合系统;涵盖存在唯一性、数值解法、与强化学习的联系及应用。
Reinforcement Learning | LLM x RL
前置知识:本文假设读者已熟悉经典 RL(MDP、policy gradient、PPO)。LLM 架构相关(decoder-only Transformer、参数估算等)的工程基础可参考:LLM Architecture Speedrun。 本文目标:从”为什么 LLM 需要 RL”开始,系统讲清现代 LLM RL 算法。 RLHF 怎么诞生:Christiano 20...
Machine Learning Basics | LLM Architecture Speedrun
本文目标:速通 LLM 的架构、参数估算、激活函数、硬件需求等工程基础。 三种 Transformer 架构(encoder-only / decoder-only / encoder-decoder) Decoder-only Transformer 的 forward pass 核心架构参数与参数量估算 主流厂商、派系、研究界常见选择 主流...
Machine Learning Basics | Minimal LLM Agent
OpenAI 后面推出了个 Response 方法,要替代 Chat Completion 了,能自动记住上下文了。但是这个方法目前只有 OpenAI 系列模型能用,其他平台用不了,所以暂时先不考虑这个。 Overview pip install MinimalLLMAgent Homepage: https://yuelin301.github.io/posts/Minim...
Multi-Agent Reinforcement Learning | PSRO: Policy-Space Response Oracles
Lanctot, Marc, et al. "A unified game-theoretic approach to multiagent reinforcement learning." Advances in neural information processing systems 30 (2017).
Misc Toolbox | Obsidian-Based Workspace
前言 Github Repo: draft01_empty 用了很久的电脑,要记点东西 要么就是随手记, 要么是找半天分类再在专门的文件夹里创建md再记录 但是 前者不好管理,记录的时候又担心之后找不到了,记录的欲望就低了 后者是启动慢,有时候灵感就丢了或者来不及记了,记起来也很痛苦。本来用博客记,但是很多东西不好公开,而且预览也不直接 本来觉得时间小事但是长期下来发现...
Economics & Game Theory | Cheap Talk
To give a formal definition, cheap talk is communication that is: costless to transmit and receive non-binding (i.e. does not limit strategic choices by either party) unverifiable (i...
Code Utils | Llama Memo
Sources Ollama. It is easy to use. Hugging Face. It provides tokenizer in Python API. Ollama Installation Download the app on the website. Install the app. Run ollama run llama3 in...
Machine Learning Basics | GPT
The following part has not been finished yet. GPT-1 Resources Radford, Alec, et al. (OpenAI) “Improving language understanding by generative pre-training.” (2018). GPT-1 = Decoder (in Tran...
Machine Learning Basics | Transformer
Encoder-Decoder Variable-length inputs Truncation and Padding Dive Into Deep Learning 10.5.3 Relation Network A blog ICLR 2017 Embedding. Enco...
Economics & Game Theory | Bargaining
An Extensive-Form Game Model Ultimatum Two people use the following procedure to split \(1\) object: Player 1 offers Player 2 some amount \(0 \leq x \leq 1\) If Player 2 accepts the outcome ...
Economics & Game Theory | Extensive-Form Games and Subgame Perfect Equilibrium
Resources This post uses the material from the following works: MIT 6.254 2010: Game Theory With Engineering Applications MIT 14.12 2012: Economic Applications Of Game Theory Tadelis, Steve...
Math Miscs | Mathematica Memos
听说python里用sympy也能做一些推导和化简,之后去看看;mathematica占硬盘太多地了 基础 $\epsilon$这种输入是Epsilon,首字母大写 Enter是换行,Shift + Enter是执行 区分大小写,大小写不同的量是两个量 函数调用,参数用中括号框起来 表达式结尾加分号;能让这个表达式的结果不输出 *是逐元素乘法,句号.是线性代数的...
Misc Toolbox | Building My Own PC
资源 装机:【【装机教程】全网最好的装机教程,没有之一】 兼容性:【【收藏血赚】DIY电脑前必须要知道的事!手把手教你检查电脑装机配置单中各硬件兼容性问题!DIY电脑中各硬件兼容性检查指南!新手小白装机前必读!】 装系统:【【装机教程】超详细WIN10系统安装教程,官方ISO直装与PE两种方法教程,UEFI+GUID分区与Legacy+MBR分区】 CPU...
Reinforcement Learning | TRPO Details
The origin paper: Schulman, John, et al. “Trust region policy optimization.” International conference on machine learning. PMLR, 2015. Overview The obejective is [J(\pi) := \mathbb{E}{\pi} \...
Economics & Game Theory | Fairness Versus Reason in the Ultimatum Game
The Game The experimenter assigns a certain sum, and the Proposer can offer a share of it to the Responder. If the Responder (who knows the sum) accepts, the sum is split accordingly between the...
Economics & Game Theory | Evolutionary Game Theory
Basic Symmetric Model with Stochastic Strategies This section is a summary of Chapter 29 of the book “Algorithmic Game Theory”1. Agents (organisms) The number of agents is infini...
Code Utils | Code Visualization
Function Call Graph Not working: pyan3 pycallgraph pycallgraph2 Inheritance Visualization Example 1: See my blog. Example 2: pyreverse -o png -p outputed_diagram main.py Agent.p...
Code Utils | LyPythonToolbox
Resources Github Repo My Full Code Toolbox Install Install: pip install LyPythonToolbox Update: pip install --upgrade LyPythonToolbox Print Tricks lyprint_separator from LyPythonToolb...
Code Utils | Github Memo
Create a Repo Click the green button New on the GitHub repo website. Do not check the Add a README file. Copy the link with the .git extension. Create a directory locally and enter it in a...
Code Utils | Python Project Template
How to Use Download LyPythonProjectTemplate Decompress it. Create a new Github project. See my blog. Copy the contents of LyPythonProjectTemplate into the root folder of your new project....
Misc Toolbox | My Website
Jekyll 读作”街口” 【转载 - Jekyll - 静态网站生成器教程双语字幕】 迁移和部署 迁移 比如要换电脑,那么这个博客怎么重新装起来 复制一份这个文件 安装环境 ruby and jekyll: https://jekyllrb.com/docs/installation/macos/ bundle install...
Misc Toolbox | MacOS Workspace
Desktop Wallpaper: A Seascape, Shipping by Moonlight - Monet False Knees - Joshua Basic Tools Hidden Bar MonitorControl GitHub Repo Wins and Magnet Window Arrangement Wins: https://wins...
Code Utils | PyTorch Toolbox
Nets Linear / MLP PyTorch Document - Linear Initialization Parameters in_features out_features bias=Ture input.shape: (*, in_features) output.shape: (*, out_...
Code Utils | Python Toolbox
This post was completed with the assistance of ChatGPT-4. Inheritance Inheritance allows a class (known as a child class) to inherit attributes and methods from another class (known as a parent ...
Reinforcement Learning | Stable Baseline 3
Getting Started Stable Baselines3 (SB3) is a set of reliable implementations of reinforcement learning algorithms in PyTorch. — Stable Baseline3 Docs. Resources [Stable Baseline3 Docs] [...
Multi-Agent Reinforcement Learning | Overcooked: A MARL Task
A Brief Intro This MARL environment remade the Overcooked game on Steam. Some features (game rules) are cut to simplify the situation. This game requires two agents to coordinate to cook. If they...
Misc Toolbox | Tools of Visual Studio Code
This note will be consistently updated. Shortcuts Command + k Command + s: Keyboard Shortcuts GOTO Command + P: Go to file Command + Shift + O: Go to symbol in editor Command + T: Go to...
Machine Learning Basics | HyperNetworks
Introduction [Paper]: HyperNetworks The following part has not been finished yet. Application in QMIX Illustration from the corresponding paper. The following statements from the paper are...
Machine Learning Basics | Decision Transformers
Decision Transformer Paper: Decision Transformer: Reinforcement Learning via Sequence Modeling - NeurIPS 2021 [Website] [Code] Illustration from the corresponding paper. Illustration fro...
Math Miscs | Contraction Mapping Theorem
Metric Space Definition of metric space Definition. A metric space is an ordered pair $(M, d)$ where $M$ is a set and $d$ is a metric on $M$, i.e., a function $d: M\times M \to \mathbb{R}$ sa...
Math Miscs | A Note on Stochastic Processes
This note partially uses the materials from the notes of MATH2750. Transition Matrix The transition kernel $\mathbf{M}$ is a square matrix of size $\vert S\vert \times \vert S\vert$. $\math...
Economics & Game Theory | Zero-Determinant Strategy
This note aims to explain the parts omitted in this paper: Press, William H., and Freeman J. Dyson. “Iterated Prisoner’s Dilemma contains strategies that dominate any evolutionary opponent.” Procee...
Economics & Game Theory | Classic Games
This note will be consistently updated. Prisoner’s Dilemma Two members of a criminal organization are arrested and imprisoned. Each prisoner is in solitary confinement with no means of commun...
Economics & Game Theory | A Memo on Game Theory
This note will be consistently updated. Rationality A rational player is one who chooses his action, to maximize his payoff consistent with his beliefs about what is going on in the game.1 ...
Multi-Agent Reinforcement Learning | Fictitious Self-Play and Zero-Shot Coordination
Fictitious Play Fictitious play is a learning rule. In it, each player presumes that the opponents are playing stationary (possibly mixed) strategies. At each round, each player thus best ...
Reinforcement Learning | Policy Gradient Details
The only way to make sense out of change is to plunge into it, move with it, and join the dance. — Alan Watts. Bellman Equations [V(s_t) = \mathbb{E}\left[ r_t + \gamma\cdot V(s_{t+1}) \right...
Machine Learning Basics | RNNs
NLP Terms NLP = Natural Language Processing Embedding In a general sense, “embedding” refers to the process of representing one kind of object or data in another space or format. It involves m...
Multi-Agent Reinforcement Learning | MARL Basics
This note has not been finished yet. Markov Models MDP Markov decision process $(S, A, \mathcal{P}, R, \gamma)$ Single-agent, fully observable, and dynamic. P...
Code Utils | Computation Graph Visualization
PyTorchviz Basics Install brew install graphviz (or here) pip install torchviz Documentation: Github Official examples: Colab If a node represents a backward fu...
Math Miscs | Dynamic Epistemic Logic
Three logicians walk into a bar. The bartender asks: “Do you all want a drink?” The first logician says: “I don’t know.” The second logician says: “I don’t know.” The third logician says: “Yes.” ...
Multi-Agent Reinforcement Learning | Theory of Mind and Markov Models
We do not see things as they are, we see them as we are. — Anaïs Nin. What is Theory of Mind? In psychology, theory of mind refers to the capacity to understand other people by ascribing menta...
Reinforcement Learning | RL Toolbox
This note will be consistently updated. PPO Tricks There are a total of 37 tricks, among which 13 are relatively core. PPO paper The 37 Implementation Details of Proximal Policy O...
Code Utils | Misc Code Toolbox
This note will be consistently updated. Tmux 太久没连服务器连这个怎么用都快忘了…不要想太复杂的操作,我用这个的原因就只有两个,第一个原因是用这个在服务器上运行python文件后,我再断开服务器的连接,这个还能在后台跑;第二个原因是,可以只用ssh连服务器一次就可以用tmux来用多个shell,比如同时跑两个python文件,这个应噶就是终...
Math Miscs | Math Toolbox
This note will be consistently updated. Optimization Basics The standard form for an optimization problem (the primal problem) is the following: [\begin{aligned} &\min\limits_{x} \quad f_...
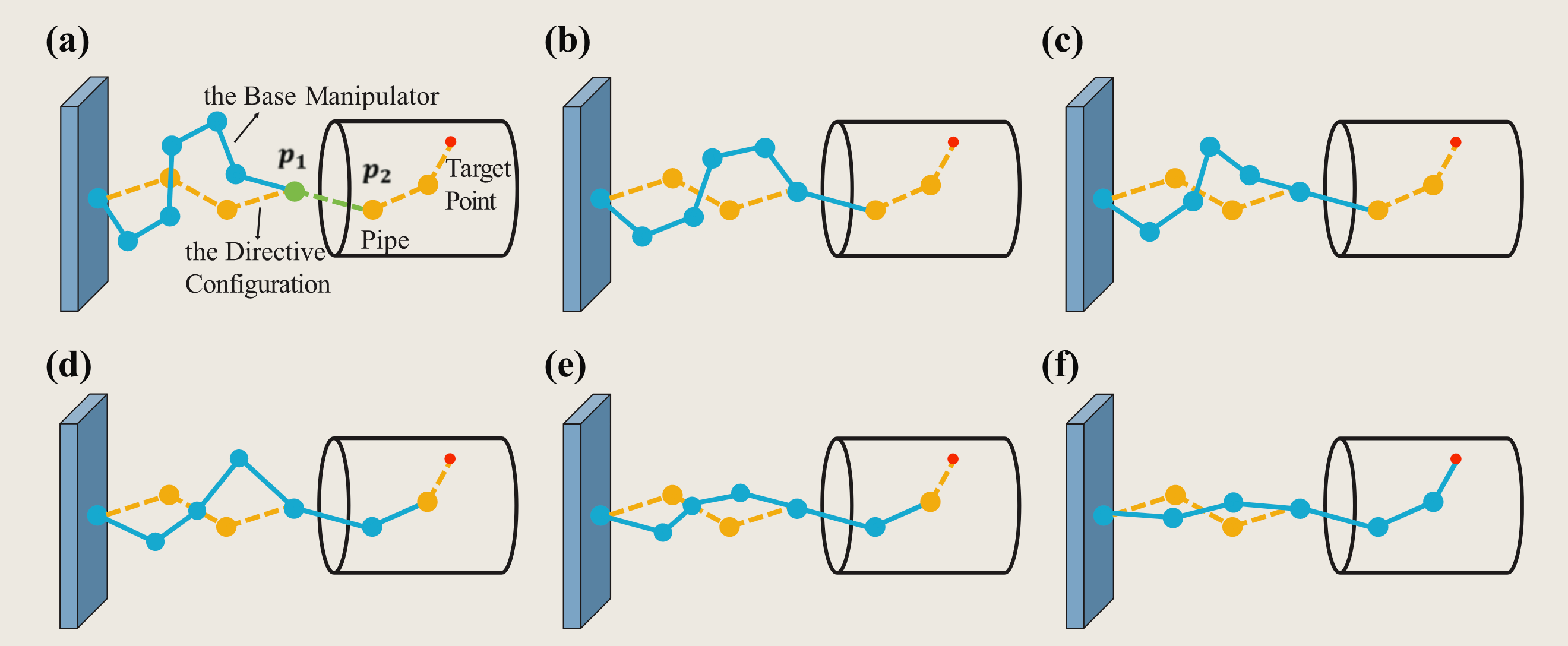
Robotics | Swinging Search and Crawling Control
Yue Lin, et al. A snake-inspired path planning algorithm based on reinforcement learning and self-motion for hyper-redundant manipulators. International Journal of Advanced Robotic Systems 2022.
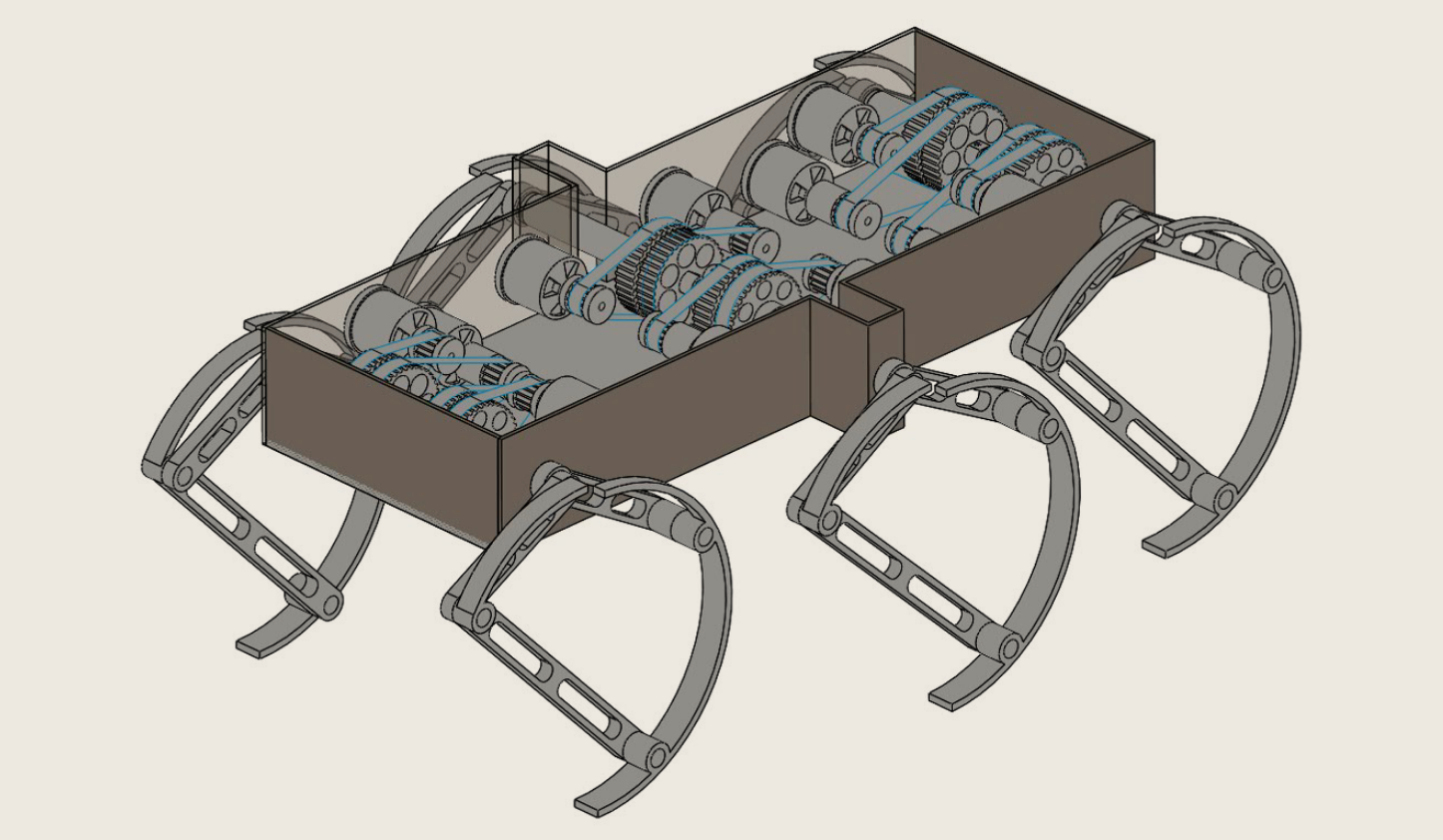
Robotics | RHex-T3: A Mobile Robot, with Hybrid Leg Design
Please be aware that the videos accompanying this article may take some time to load, depending on the speed of your internet connection to GitHub. Innovative design and simulation of a transform...